(2023-04-04) ReazonSpeechの最新モデルを公開しました¶
ReazonSpeechは、世界最大のオープン日本語音声コーパスを構築するプロジェクトです。
このプロジェクトのポイントとして「時間とともにコーパス量が増加する」という点があります。 放送音源を素材データとしているため、解析対象のデータは毎日刻々と増えており、 これに計算リソースを投下すれば、新しいコーパスを継続的に抽出することができます。 この方法で作成できるコーパスは、年間で10000時間以上になります。
ヒューマンインタラクション研究所では、この日々増えていくコーパスを利用して、 音声認識モデルを定期的に訓練しています。
今回、研究所で定期構築する最先端の音声認識モデルを一般公開することにしましたので、 その詳細についてお伝えします。
最新モデルを取得・利用するには¶
最新モデルは、Hugging Faceの reazonspeech-espnet-next で公開しています。
利用方法ですが、ReazonSpeechモジュールから簡単に使えるようにしています。 v1のフィードバックを反映して、なるべく手軽に使えるように、ライブラリの実装面でも諸々の改善を図りました。
具体的には次のように使うことができます:
基本的な利用方法
# Virtual Environmentを作成
$ python3 -m venv venv
$ . ./venv/bin/activate
# ReazonSpeechをインストール
$ pip install wheel
$ pip install git+https://github.com/reazon-research/reazonspeech.git
# reazonspeechコマンドで音声を文字起こしできます
$ reazonspeech test.wav
Pythonコードでの利用例
import reazonspeech as rs
# 音声ファイルを直接デコードする
for caption in rs.transcribe("test.wav"):
print(caption)
実はこの最新モデルでは、長い音声も問題なく処理できるようになっています (一定の長さを超えるデータについては、自動的に分割する仕組みが入っているのですが、 この機能については稿を改めて詳しく解説します)。 数十分を超えるような長い音声ファイルを与えてもOKです。
ReazonSpeechの詳しい使い方は クイックスタート を参照ください。
リリースサイクルについて、このHugging Faceのモデルはローリングリリースで運用する予定です。 研究所で改善が確認できた都度、なるべく早いタイミングで新しいモデルをプッシュします [1]
最新モデルの精度について¶
この最新モデルがどの程度の水準かですが、実は今年1月にv1をリリースしてから、 精度面で大きく進歩しています。
以下に、 JSUT ・ Common Voice ・ TEDx の3つのベンチマークに対して精度を測定した結果を示します。 比較として、ReazonSpeech v1とOpenAI Whisperの各モデルの測定結果を併記します [2]
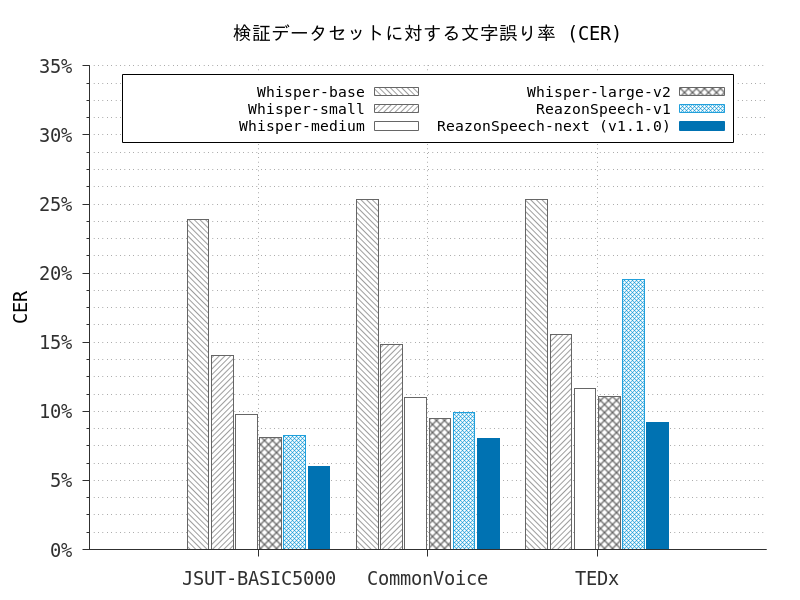
このグラフのY軸はCER(文字誤り率)で、低ければ低いほど高い精度であることを示します。 ReazonSpeech v1との比較で、ReazonSpeech-nextは認識精度が更に約2%向上しています。
フィードバック大歓迎です!¶
この記事では、最新のReazonSpeech深層学習モデルの reazonspeech-espnet-next について紹介しました。
ReazonSpeechプロジェクトでは、音声処理コミュニティからのフィードバックを受け付けています。 プロジェクトに関心がある・この部分を改良したい等のアイデアがあれば、 GitHub のIssueまたはDiscussionにて一緒に議論しましょう!