(2024-08-01) ReazonSpeech v2.1: Setting a New Standard in Japanese ASR¶
Today, we're excited to announce ReazonSpeech v2.1. In this release, we publish ReazonSpeech-k2-v2, an open-source Japanese ASR model which sets new records in benchmark tests. It is built on the Next-gen Kaldi framework and distributed in the platform-neutral Open Neural Network Exchange (ONNX) format. ReazonSpeech-k2-v2 excels in accuracy, compactness, and inference speed, and can run on-device without GPU.
We published the ReazonSpeech-k2-v2 model under the Apache 2.0 license. The model files and the inference code are readily available on Hugging Face and GitHub.
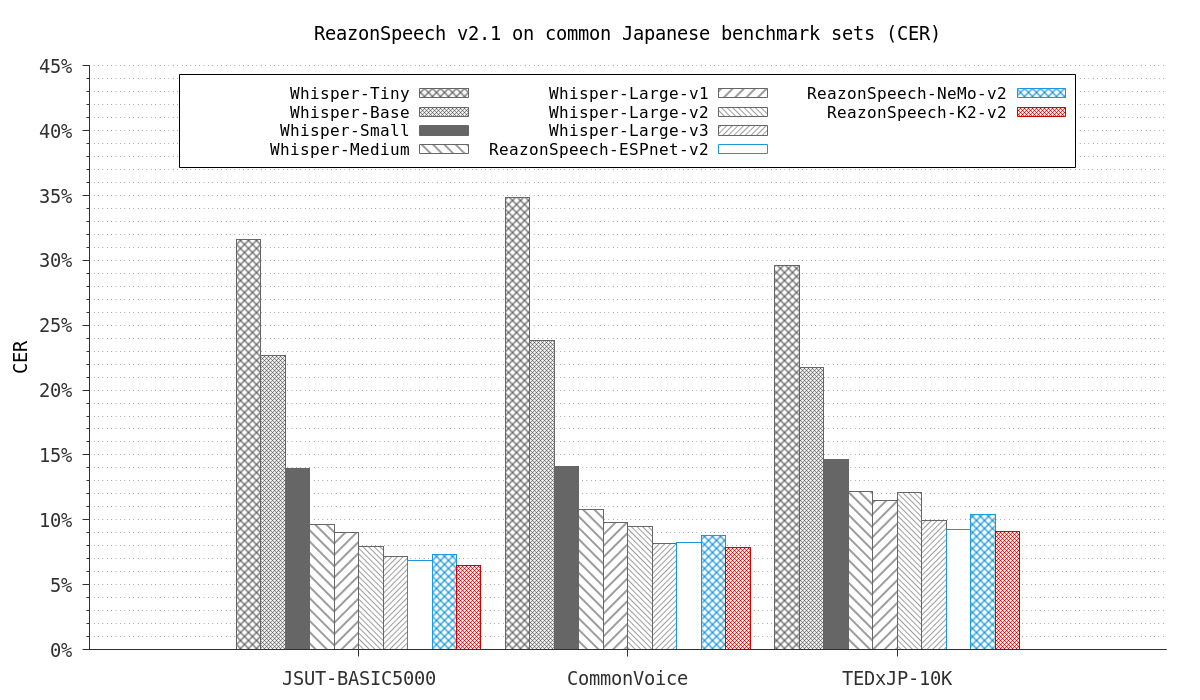
Figure 1: ReazonSpeech v2.1 on common Japanese ASR benchmark tests¶
What is ReazonSpeech v2.1?¶
ReazonSpeech v2.1 represents the latest iteration of Reazon Human Interaction Lab's ASR research. This release introduces a new Japanese ASR model that:
Outperforms existing Japanese ASR models on JSUT-BASIC5000 [1], Common Voice v8.0 [2], and TEDxJP-10K [3] benchmark sets (see the chart above).
Excels in compactness, only having 159M parameters.
Excels in inference speed, one of the fastest models to process short audio inputs.
What enables such outstanding performance is the state-of-the-art Transformer called Zipformer [4]. We trained this novel network architecture on 35,000 hours of Reazonspeech v2.0 corpus, which revealed a best-in-class performance.
Tip
For further details about the ReazonSpeech-k2-v2 model, the full training recipe is available on k2-fsa/icefall.
Easy deployment with ONNX¶
The ReazonSpeech-k2-v2 model is available in the ONNX format, significantly enhancing its versatility across a wide range of platforms. Leveraging the ONNX runtime, which is independent of the PyTorch framework, simplifies the setup process, facilitating seamless integration across diverse environments. This adaptability ensures practical application on various devices even without GPU, including Linux, macOS, Windows, embedded systems, Android, and iOS.
For more details about the supported platforms, please refer to the Sherpa-ONNX's documentation.
Reduce memory footprint with quantization¶
We also released a int8-quantized version of the ReazonSpeech-k2-v2 model.
The quantized model exhibits a significantly smaller footprint, as shown
in the following table.
FILE |
FILE SIZE (FP32) |
FILE SIZE (INT8) |
|---|---|---|
Encoder |
565 MB |
148 MB |
Decoder |
12 MB |
3 MB |
Joiner |
11 MB |
3 MB |
These quantized models are up to 10x smaller than comparable ASR models like Whisper-Large-v3, enabling their deployment on a wide range of devices with computational constraints. Notably, when used with a non-quantized decoder, these quantized models maintain accuracy levels comparable to their non-quantized counterparts. This enables the deployment of our model even on devices with very limited computational capacity.
Model Name |
JSUT |
Common Voice |
TEDxJP-10K |
|---|---|---|---|
ReazonSpeech-k2-v2 |
6.45 |
7.85 |
9.09 |
ReazonSpeech-k2-v2 (int8) |
6.63 |
8.19 |
9.86 |
ReazonSpeech-k2-v2 (int8-fp32) |
6.45 |
7.87 |
9.15 |
Whisper Large-v3 |
7.18 |
8.18 |
9.96 |
ReazonSpeech-NeMo-v2 |
7.31 |
8.81 |
10.42 |
ReazonSpeech-ESPnet-v2 |
6.89 |
8.27 |
9.28 |
Future goals¶
With this release, we have significantly enhanced both the speed and accuracy of our Japanese ASR models. By making our model open-source on the K2 Sherpa-ONNX platform, we have greatly improved accessibility for a broad range of users and developers across various platforms.
Looking ahead, we are committed to further advancing our models by expanding our dataset, developing streaming ASR capabilities, and incorporating multilingual data to create an exceptional bilingual English-Japanese ASR model.
This release represents a major milestone, and we are excited to continue pushing the boundaries of Japanese speech processing technology in the future. Currently, ReazonSpeech-k2-v2 can process longer segments of audio with the help of voice activity detection (VAD). In the future, we plan to release a streaming version of this model which can innately support real-time transcription.