(2024-02-14) ReazonSpeech v2.0: 音声モデルの高速化とコーパスの大幅な拡大¶
2024年2月14日に、ReazonSpeechの最新バージョン v2.0 を公開したことをお知らせします。
ReazonSpeech v2.0では、音声認識モデルの飛躍的な性能アップデートを実現しており、 また公開する日本語音声コーパスも35000時間に大幅に拡大しています。
この記事では、今回のアップデートのハイライトをお伝えします。
ReazonSpeech v2.0で何がリリースされたのか?¶
今回、ヒューマンインタラクション研究所では次の3点をリリースしました。
対象 |
主なトピック |
URL |
|---|---|---|
音声認識モデル (NeMo) |
|
|
音声認識モデル (ESPnet) |
|
|
日本語音声コーパス |
|
それぞれのリリースアセットの詳細は、表の各リンクから参照できます。 この記事の以降では、今回のリリースの特に重要なポイントについて解説を加えます。
音声認識モデルの大規模アップデート¶
ReazonSpeech v2.0では、従来のESPnetに加え、NVIDIA NeMoベースのモデルの提供をスタートします。
この新しく提供するモデルの最大の特徴は、高速かつ高精度に日本語を認識できる点です。 次の図をご覧ください。
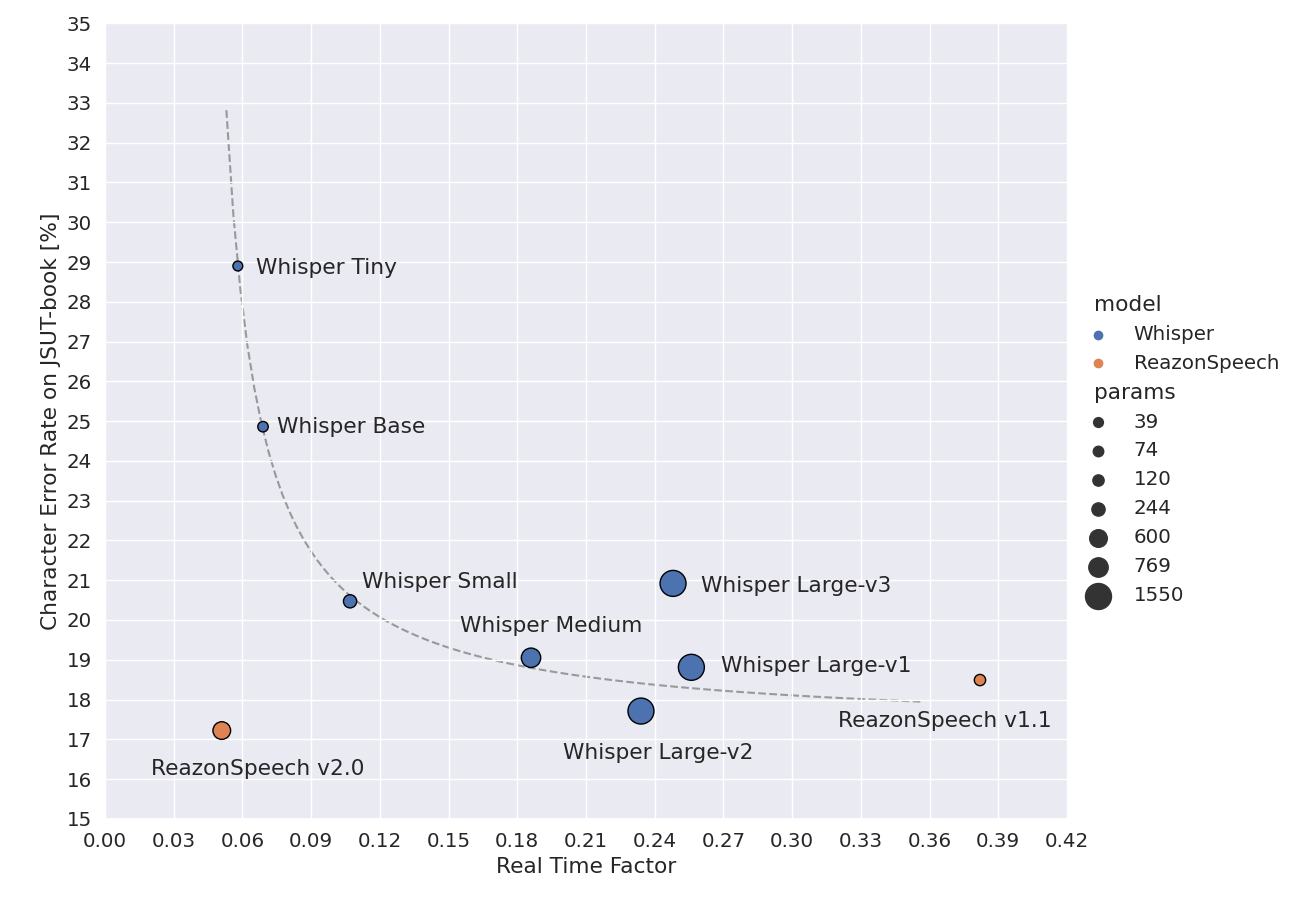
この図は、日本語音声認識モデルの処理速度と認識精度を散布図にプロットしたものです。 縦軸と横軸ともに、原点に近いほど高い性能であることを表します。 [1]
この図からいくつかのポイントが見てとれます:
まず、音声認識において、速度・精度の間にトレードオフの関係があることが確認できます。 一般に、高精度の音声認識には、パラメーター数の多い巨大なモデルが必要となり、 その分だけ処理時間が長くなります。図の点線のカーブは、この関係を示すものです。
従来のモデル群は、実質的に同じトレードオフの前線に位置していました。 例えば、WhisperのSmallモデルはMediumモデルの1.7倍速で推論を行えますが、その分だけ精度が劣化します。
今回、ReazonSpeech v2.0では、認識精度と処理速度の両立を実現しました。
ReazonSpeech v1.1と比較すると、精度は保ったまま、推論速度が7倍以上に高速化しています。
同じことをOpenAI Whisperとの比較で言い替えると、Whisperの最も小さいTinyモデルの速度で、 最も大きいLargeモデル相当の精度を達成できています。
さらに、ReazonSpeech v2.0の認識精度の頑健性を示すために、 JSUT-BASIC5000 [3] 、Common Voice v8.0 [4] 、 TEDxJP-10K [5] の3つのデータセットに対して測定を行いました。 その結果が次の図です。
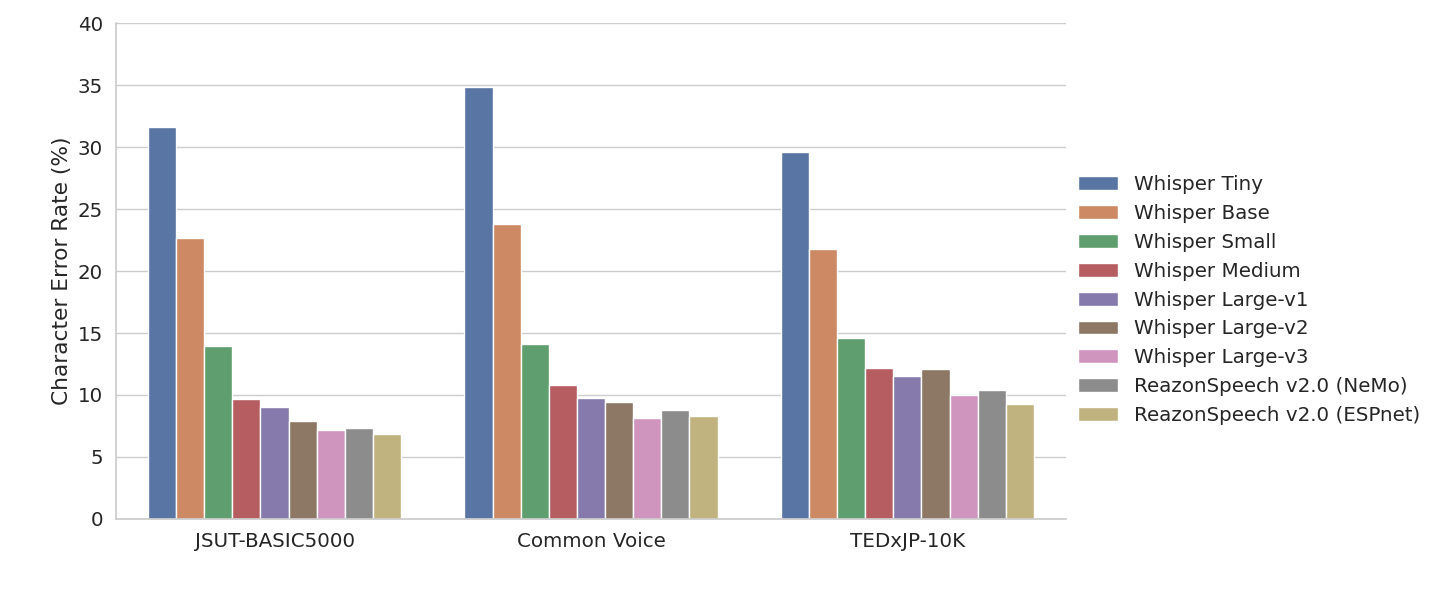
様々なデータセットに対して、ロバストに推論を実行できていることが確認できます。
今回、公式サイトでは ReazonSpeechの音声認識デモ を用意しています。 次のように、ファイルのドラッグ&ドロップで簡単に音声をテキストに変換できます。
また、ReazonSpeechモデルの使い方を クイックスタート と HowToガイド で解説しています。 実際に音声認識モデルを使ってみた感想などのフィードバックをお待ちしています。
従来比1.8倍の日本語音声コーパス¶
ReazonSpeechは世界最大のオープン日本語音声コーパスの構築を目指すプロジェクトです。
昨年1月に、放送音声から抽出した19000時間の日本語音声コーパスを公開しました。 これを実現した技術の詳細は 言語処理学会の年次大会で発表した論文 で詳しく述べました。
今回は、その手法をさらに推し進め、35000時間のコーパスを構築しました。 これは昨年比で1.8倍に相当する規模となり、英語圏の大規模データセットと比較しても遜色のないスケールに達しています。
さらに、実際のユースケースに配慮し、今回のリリースからサブセットデータの提供も拡大します。 具体的には、全件データに加えて、次のようなサブセットを提供します。
タグ |
サイズ |
収録時間数 |
|---|---|---|
tiny |
600MB |
8.5 時間 |
small |
6GB |
100 時間 |
medium |
65GB |
1000 時間 |
large |
330GB |
5000 時間 |
all |
2.3TB |
35000 時間 |
これらのデータセットの具体的な利用方法は HowToガイド に記述しています。
今後の展開¶
当研究所では、ユーザがより効率的に情報伝達を行うための技術研究の一環として、 音声コーパスと音声認識モデルの研究開発を行ってきました。
今回のリリースはその一つの大きなマイルストーンであり、 今後も日本語音声処理技術の発展に向けてより一層研究を進めて参ります。