ReazonSpeech¶
ReazonSpeechは、世界最大のオープン日本語音声コーパスを構築するプロジェクトです。
日本語音声技術の推進を目的として、35,000時間の日本語音声コーパスを公開しています。
音声認識モデル・コーパス作成ライブラリをオープンソースライセンスで配布しています。
リソース |
ライセンス |
URL |
|---|---|---|
音声認識モデル |
||
音声処理ライブラリ |
||
日本語音声コーパス |
CDLA-Sharing-1.0 (ただし利用目的は著作権法30条の4に定める情報解析に限る) |
https://huggingface.co/datasets/reazon-research/reazonspeech |
研究論文 |
ReazonSpeechコーパスのサンプル音声¶
ラベル |
音声 |
|---|---|
気象庁は、雪や路面の凍結による交通への影響、暴風雪や高波に警戒するとともに、雪崩や屋根からの落雪にも十分注意するよう呼びかけています。 |
|
はやくおじいさんにあのおとこのはなしをきかせたかったのです。 |
|
ヤンバルクイナとの出会いは18歳の時だった。 |
|
H2Aは、打ち上げの成功率は高い一方、1回の打ち上げ費用がおよそ100億円と、高額であることが課題となっていました。 |
|
持ち主とはぐれた傘が風で舞い看板もなぎ倒されてしまったようです。 |
ReazonSpeechの音声認識モデルの性能¶
ReazonSpeechの音声認識モデルは最先端の性能を実現しています。
次の図は JSUT-bookコーパス を検証データセットとして、 日本語音声認識モデルの処理速度と認識精度を散布図にプロットしたものです。
縦軸と横軸ともに、原点に近いほど高い性能であることを表します。
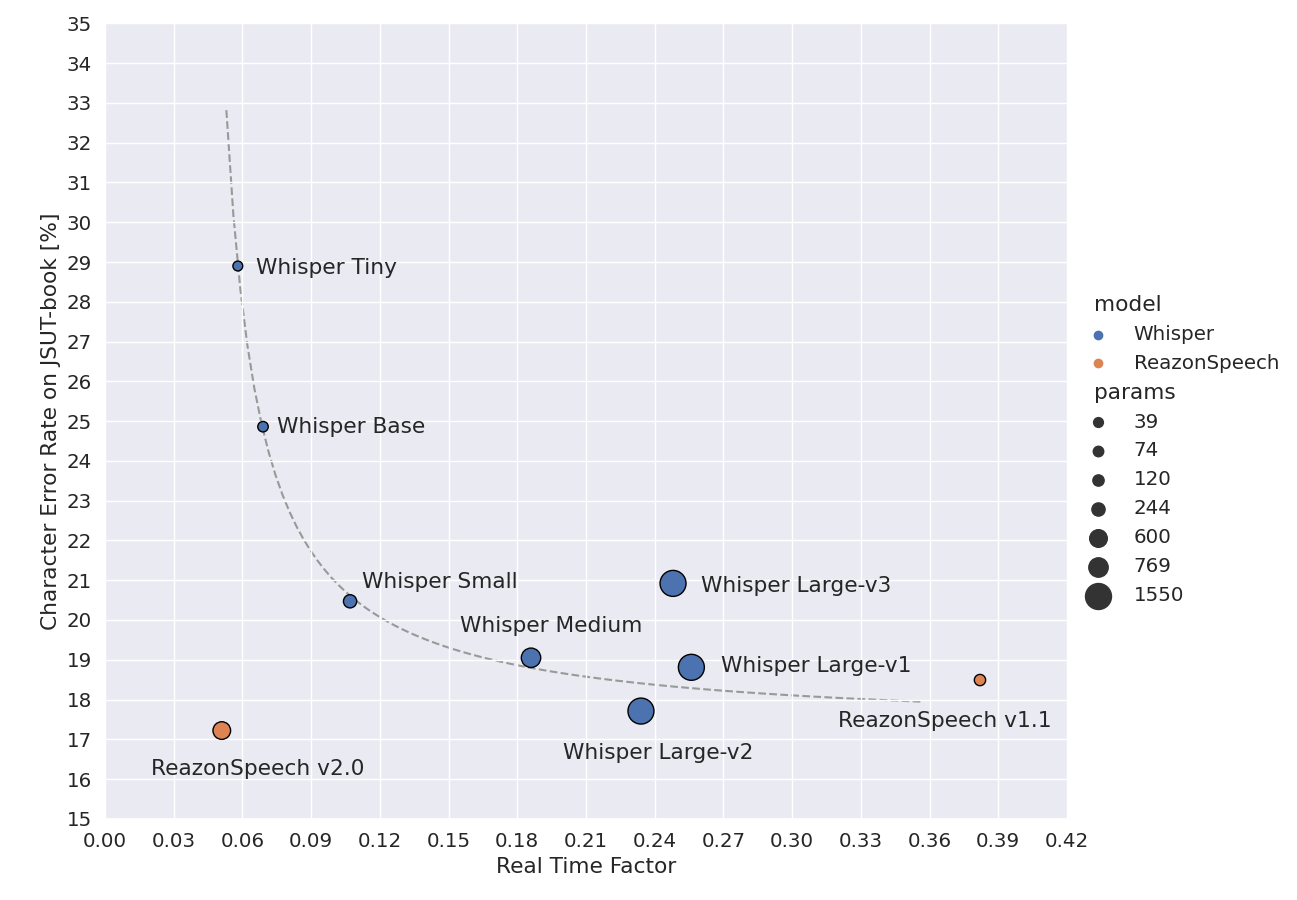
文字誤り率で測定した精度
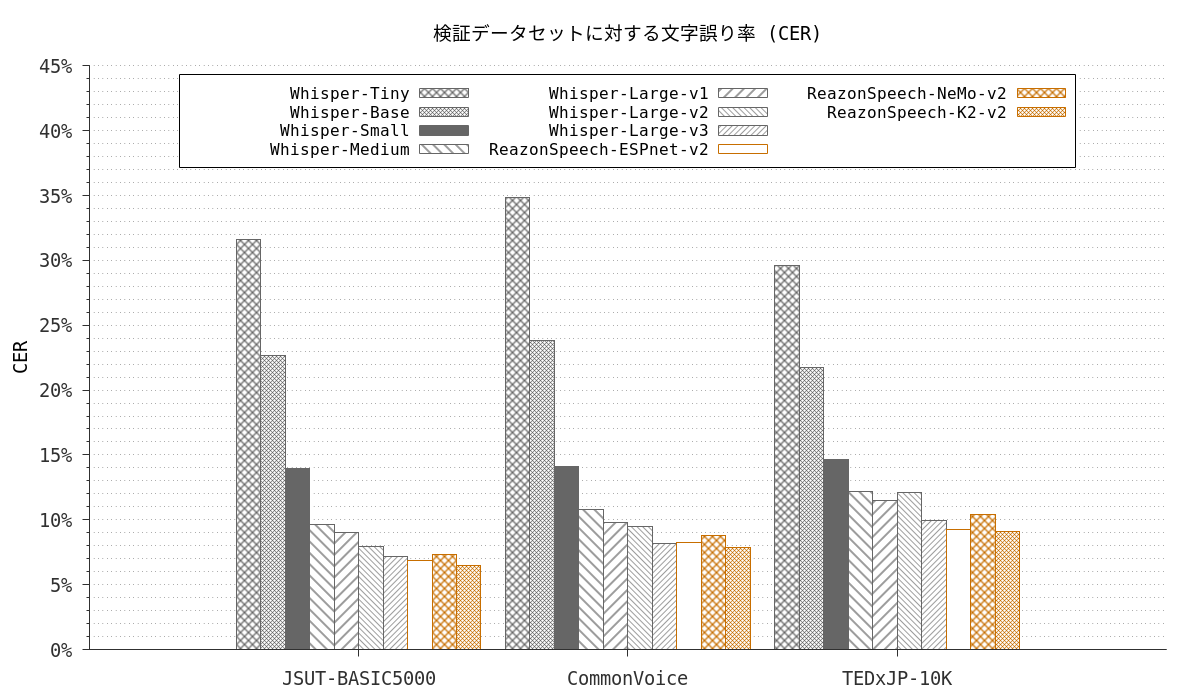
次の図は、JSUT-BASIC5000 [1], Common Voice v8.0 [2], TEDxJP-10K [3] を検証データセットとして、日本語音声認識モデルの 精度を比較したものです。
縦軸が低ければ低いほど、高い性能であることを表します。